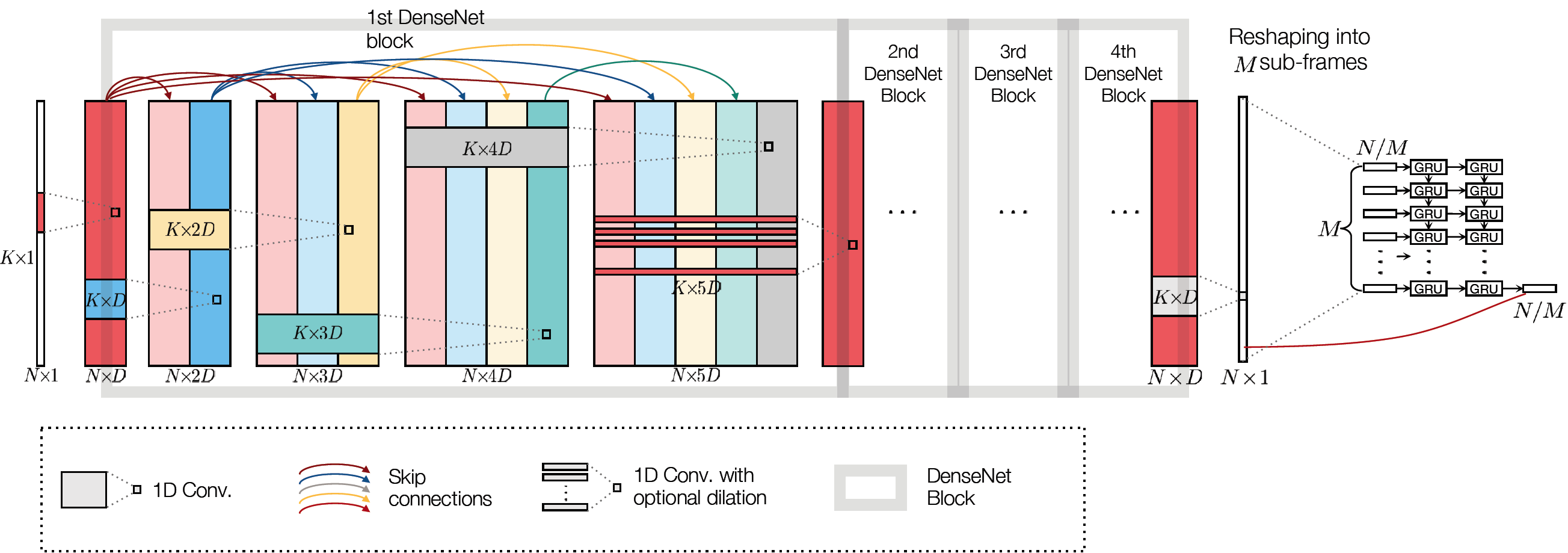
In speech enhancement, an end-to-end deep neural network converts a noisy speech signal to a clean speech directly in the time
domain without time-frequency transformation or mask estimation.
However, aggregating contextual information from a high-resolution
time domain signal with an affordable model complexity still remains challenging.
In this paper, we propose a densely connected
convolutional and recurrent network (DCCRN), a hybrid architecture, to enable dual-staged temporal context aggregation. With the
dense connectivity and cross-component identical shortcut, DCCRN
consistently outperforms competing convolutional baselines with an
average STOI improvement of 0.23 and PESQ of 1.38 at three SNR
levels. The proposed method is computationally efficient with only
1.38 million parameters.
The generalizability performance on the
unseen noise types is less competitive comparing to Wave-U-Net with 7.25
times more parameters.
Fig 1. A trainable soft-to-hard quantization scheme used in the digitalization of LPC coefficients and residuals.
Denoised Samples
Machine guns
Models
-5 dB
0 dB
+5 dB
Unprocessed
Gated ResNet
DenseNet
Dilated DenseNet
DenseNet+GRU
Ours
Clean speech
Cicadas
Models
-5 dB
0 dB
+5 dB
Unprocessed
Gated ResNet
DenseNet
Dilated DenseNet
DenseNet+GRU
Ours
Clean speech
Motorcycles
Models
-5 dB
0 dB
+5 dB
Unprocessed
Gated ResNet
DenseNet
Dilated DenseNet
DenseNet+GRU
Ours
Clean speech
Humming birds
Models
-5 dB
0 dB
+5 dB
Unprocessed
Gated ResNet
DenseNet
Dilated DenseNet
DenseNet+GRU
Ours
Clean speech
Computer keyboard clicking
Models
-5 dB
0 dB
+5 dB
Unprocessed
Gated ResNet
DenseNet
Dilated DenseNet
DenseNet+GRU
Ours
Clean speech
References
[1] Ke Tan, Jitong Chen, DeLiang Wang, "Gated Residual Networks with Dilated Convolutions for Monaural Speech Enhancement," in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2018.
[2] Chien-Feng Liao, Yu Tsao, Xugang Lu, Hisashi Kawai, "Incorporating Symbolic Sequential Modeling for Speech Enhancement," in the 20th Annual Conference of the International Speech Communication Association INTERSPEECH, 2019.