It is common to leverage human perception of sound,
or psychoacoustics, in conventional audio coding technology, to
reduce the bitrate while preserving the perceptual quality in
the decoded audio signals. When it comes to using deep neural
networks for this compression task, however, the objective nature
of the loss function tends to lead to a suboptimal sound quality
as well as a high run-time complexity due to the large model
size. In this work, we present psychoacoustic calibration schemes
to re-define the loss functions of neural audio coding systems,
so that the decoded signals are perceptually more similar to
the original. Moreover, the proposed psychoacoustic optimization
can also result in a more streamlined system. To this end, we
derive novel loss functions from the empirically found global
masking threshold. Experimental results show that the proposed
psychoacoustic loss functions yield better performances than an
ordinary autoencoding-based baseline codec, which has up to
100% more parameters and consumes 36.5% more bits per
second. The performance is comparable with the commercial
MPEG-1 Audio Layer III codec in 112 kbps.
Decoded Samples
The bitrate for uncompressed waveforms is 1.411 Mbps, the same as CD's with the stereo setup.
For the mono setup in this work, the uncompressed bitrate is 705.6 kbps.
High Bitrates, 44.1 kHz
Fraunhofer MP3, 112 kbps
Basic Neural Codec, 131 kbps, 0.9 million parameters
Proposed, 112 kbps, 0.9 million parameters
Reference
Fraunhofer MP3
Basic Neural Codec
Proposed
Low Bitrates, 32 kHz
Fraunhofer MP3, 64 kbps
Basic Neural Codec, 79 kbps, 0.9 million parameters
Proposed, 64 kbps, 0.45 million parameters
Reference
Fraunhofer MP3
Basic Neural Codec
Proposed
Details to be released...
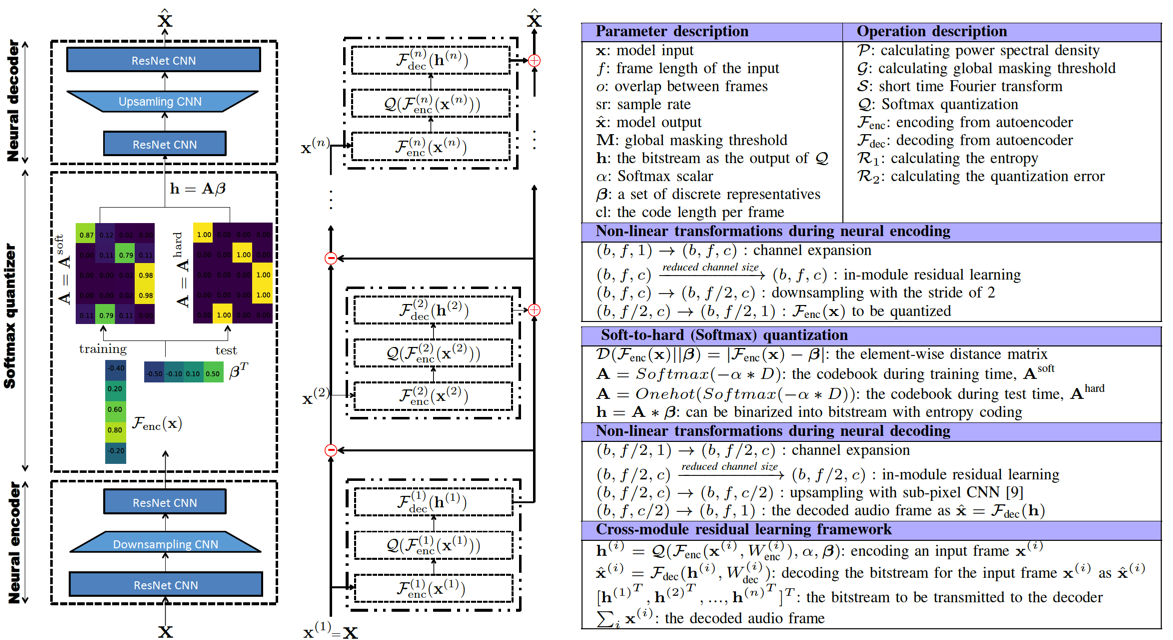
Fig 1. Our neural audio codec is of low model complexity with only 0.45M parameters, which features a trainable Softmax quantizer.
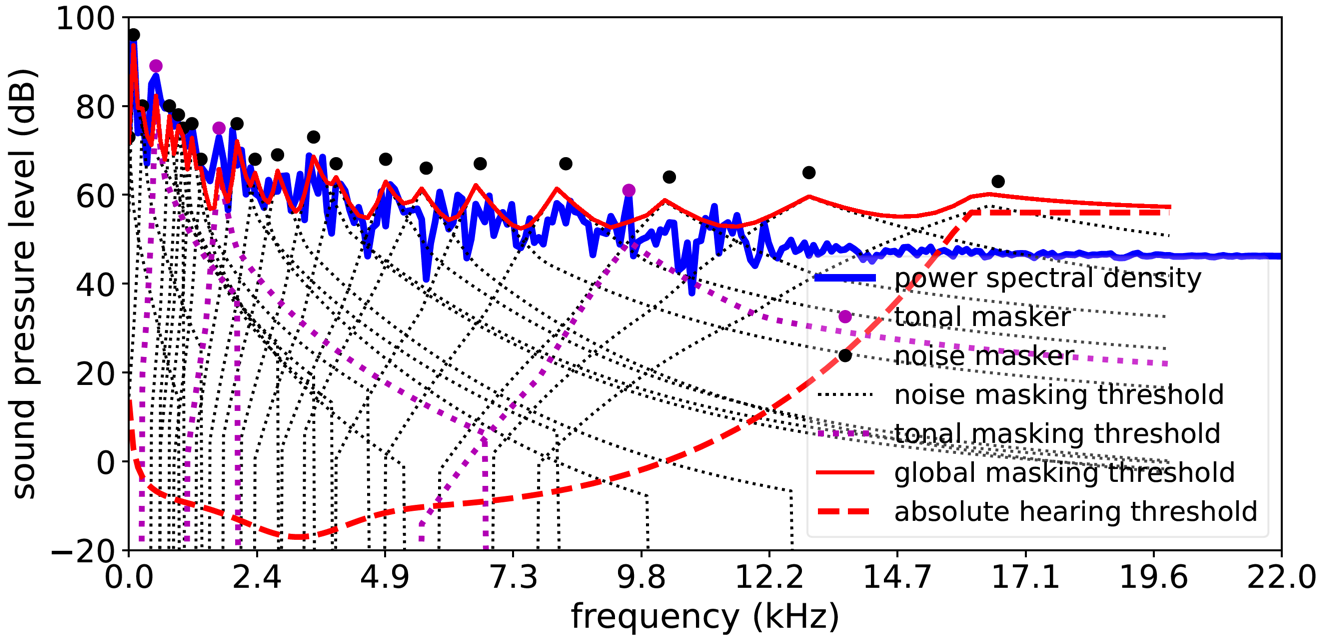
Fig 2. A psychoacoustic model (PAM) detects tonal/non-tonal maskers, and calculates individual/global masking threshold.
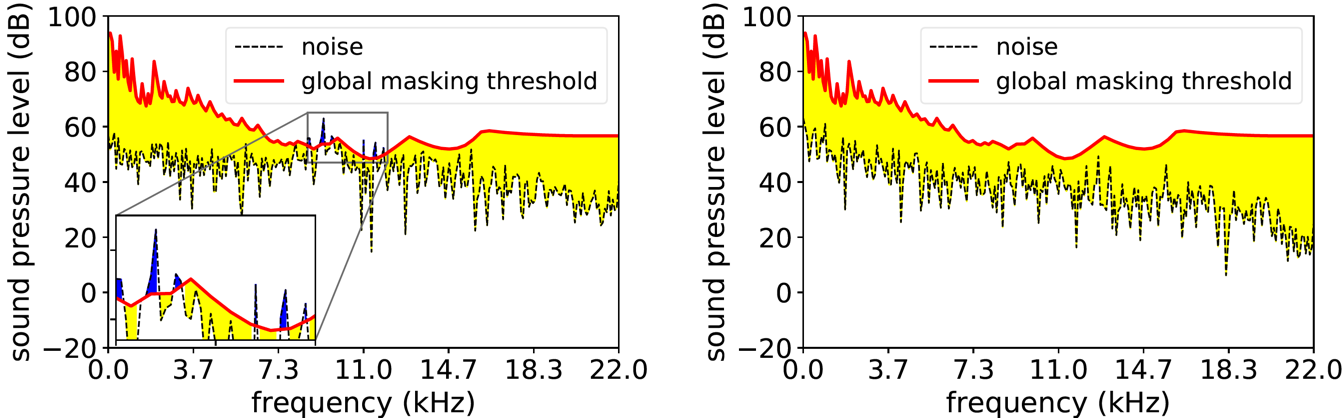
Fig 3. Comparison before (left) and after (right) psychoaoustical calibration: with the noise fully masked, the decoded audio achieves near transparent quality.